
Yes yes. I too cannot believe how brave and novel of a take this is, but hear me out.
So the work I’ve been doing recently has involved retrieving public posts from twitter/reddit/wherever so that smart people can run Topic Modeling on it to figure out what kinds of things different people/groups/internet-users are talking about. These smart people are using their skills to investigate important things like how people talk about their medical conditions and I admire their hard work. I, on the other hand, am both less imaginative and more prone to doing things because they sound like fun. So, in an effort to teach myself more about Topic Modeling (lol) I decided to run one on r/medicalschool.
If you’re unfamiliar with Reddit, it’s what I would describe as late-stage internet forum culture. It’s a website that allows users to join (relatively) smaller sub-communities (called subreddits) where they can discuss things they’re all interested in. Anything you think of that people are into, there’s probably a semi-active community of devotees on Reddit. You can keep up to date with Football news, engage in discussions about the best Netflix show, or revel alongside adherents to a favorite food.
As you may have surmised by now, r/medicalschool is a place where medical students congregate and discuss being in medical school. You can already guess at a few topics that show up often: residency match, board exams, medicine in general. But what else do they all talk about!? Are there other patterns/topics that get discussed that aren’t as obvious? All fun questions we can answer (maybe) with Topic Modeling.
If you have spent any amount of time on Reddit, you may have already found an issue with this project, which is that a significant amount of content on a lot of subreddits these past few years consists of memes. This presents problems on a few fronts.
- My model can’t read text superimposed on images, which is what most memes are.
- Memes (and the subsequent comments) operate on varying and oftentimes nested levels of abstraction and sarcasm.
- The context of the memes is often the meat of the message which means an understanding of the cultural significance behind the memes is essential to even guessing at what’s going on.
- Lots of memes are videos. No idea how to even start this.
Now this isn’t to say that no one is even trying because they definitely are, but what these teams are doing is super complicated and currently way over my head. I may come back to this at some point but for now, I just focused on text.
Topic Modeling
So, disclaimer: after a handful of months of poking at this project, I still only vaguely understand what TM even is and probably (embarrassingly) can only identify really narrow and unimaginative use-cases for it. So, please do not read this is an explainer, but rather as documentation of my journey to understanding it. Basically, if you’re really interested in it, don’t even bother reading this and instead refer to actual literature.
Like so much else in data science/programming/life, my knowledge consists of disjointed, slapped together parts from different sources; all of which I only somewhat understand.

What TM does under the hood is draw associations between words it sees occurring close to each other. It does this over the entirety of the corpus you feed it, and it spits out topics (the number of which you decide, we’ll talk about this more later) consisting of a list of words, weighted by their relative importance to the topic at hand.
What you do with this information is sort of up to you. You can just look at topics. You can feed the model new texts and it will spit out what topic it thinks it’s talking about. You can think up a bunch of easy applications for this in things like customer service/marketing where companies feed reviews/tweets whatever into a model and it tells them what % of the reviews complain about durability, aesthetics, competing products etc… You can run the topics/text through sentiment analysis to see if these topics are positive, negative, or some flavor in-between. I’ve done almost no research on the matter but I’m 99% sure that most companies already do this and that anyone who isn’t doing this is behind the times and missing out on a wealth of data. This is the extent to which I can semi-confidently explain what TM is. The rest of this section will be (probably pointless) descriptions of how to actually implement Topic Modeling.
Data
The first thing you need to do is ‘acquire’ the data. In my case, it involved recycling code I had used to scrape a subreddit for work. You can find the script and subsequent relevant code here. But basically, there are a few different options for accessing Reddit’s API to retrieve batches of submissions and comments. I went with PushShift which is sometimes a bit behind, especially on really active subreddits (like r/wallstreetbets). It was fine for the my purposes where losing the most up-to-date posts is a fine tradeoff for ease of access to the entire history of the subreddit in a reasonable time frame. PRAW is a python wrapper for Reddit’s actual API, but for whatever reason I found working through Pushshift to be easier. So the script is basically running loops on timestamps to pull 100 submissions at a time.
It ended up taking something like 12 hours to run. I’m unsure if this is a limitation of my hardware, Pushshift’s severs (I was extra friendly to it), or of my poorly written code; likely a combination of all 3, extra weight on my poor logic. I wound up with something like 1.5 million combined submissions and posts which makes some sense given the 300,000+ members and a constantly rotating cohort of participants, assuming that participation wanes after graduation.
Clean and Lemmatize
So the data is full of pretty messy stuff that doesn’t lend itself well to Topic Modeling. You need to remove any errant HTML, punctuation, blank lines, deleted posts (show up as ‘[deleted]’ on reddit), emojis, and hyperlinks; regex (AAAAHHHHHHHHH) is more or less required. To run the model, your script needs to label or ‘tokenize’ to each unique word in the corpus so that all it needs to draw associations with is integers, which makes enough sense. To reduce repetition of tokens, you need to do things like convert the entirety of the corpus to lowercase (so ‘hello’ and ‘Hello’ don’t show up as different tokens), and to lemmatize the words which removes tenses (‘study’ and ‘studying’ represent more or less the same idea, no need to count it twice). Next, you remove stop words, which are commonly used words in language that don’t carry any meaning but are just used for grammar purposes like ‘the’ or ‘and’.
A note on this part: data cleaning takes forever. I make it seem like there’s an order to all of this (and maybe it’s because I am particularly bad at this) but I had to double back several times after running models and discovering that I had left out a step, or some regex (AAAHHHHHHHH) didn’t work as I expected it to, or there was yet another type of data messiness that I had left out.
LDA Modeling and Hyperparameter Tuning
After all of that, you make a dictionary which maps each token to an actual word so that you ‘rehydrate’ what your model spits back out. Then, you convert your corpus into a data format that your given model will accept; in the case of LDA (Latent Dirichlet Architecture), it was a list of lists.
I ended up using the Gensim library’s LDA model mostly because it’s based on python (the language I am most comfortable with), and because there was a plethora of support built up around it (lots of errors lazily pasted into stackoverflow showed up directly referencing Gensim!).
So the way things are supposed to be done is, you run the model on a smaller subset of your dataset (assuming your dataset is pretty large), and use a combination of eyeballing and serially running models to tune your hyper parameters. Some of these parameters include adjusting the number of topics, and various topic ‘densities’. If you run a model with too few topics, you don’t capture all the data that’s available to you, and sometimes the topics you end with are a jumbled mess because they represent several actually distinct topics. The topic density parameters (alpha and beta) were a bit esoteric but from my understanding represented how many topics might be in each ‘document’, and then how many words each topic consisted of.
I ended up running something like 300 different models (thanks Google Colab!) using different values for # of topics, alpha, and beta. This took forever. Gensim’s LDA model has process that utilizes multi-threading but both my personal computer (2013 MacBook Pro) and Google’s VM only had two cores so these models basically ran single-threaded. To my knowledge, Gensim’s implementation can’t utilize GPUs. There are mentions scattered around the internet of models that can use GPUs, but they’re either not public or were written in languages I’m less than comfortable with. C’est la vie.
Chart Party!
So I tried my level best to find a way to imbed the interactive chart but apparently I’m not cool enough for Jekyll. But also all of the helpful Medium articles I found on the matter just posted screenshots of their visualizations so maybe I’m not alone in not being able to make it work. I have a nagging suspicion though that you can make it work by just opening the HTML file that’s in the repo in your browser, but no promises.
So each of the circles on the left represents what the model thinks is a “Topic”. Overlapping circles means that the topics share a bunch of words in common. Generally this is bad and means you have too many topics, but in the case of a subreddit dedicated to medical school, there’s bound to be some overlap. They’re just numbered so we get to call them whatever we feel like. The chart on the right shows the frequency that each word appears in documents tagged with this topic. The red bar shows frequency within the topic, the blue bars ‘beneath’ them show how frequently the word is used outside of the topic. You generally want to see lots of red and not a whole lot of blue but with more common words it’s sort of unavoidable.
Anywho, here are some screenshots:
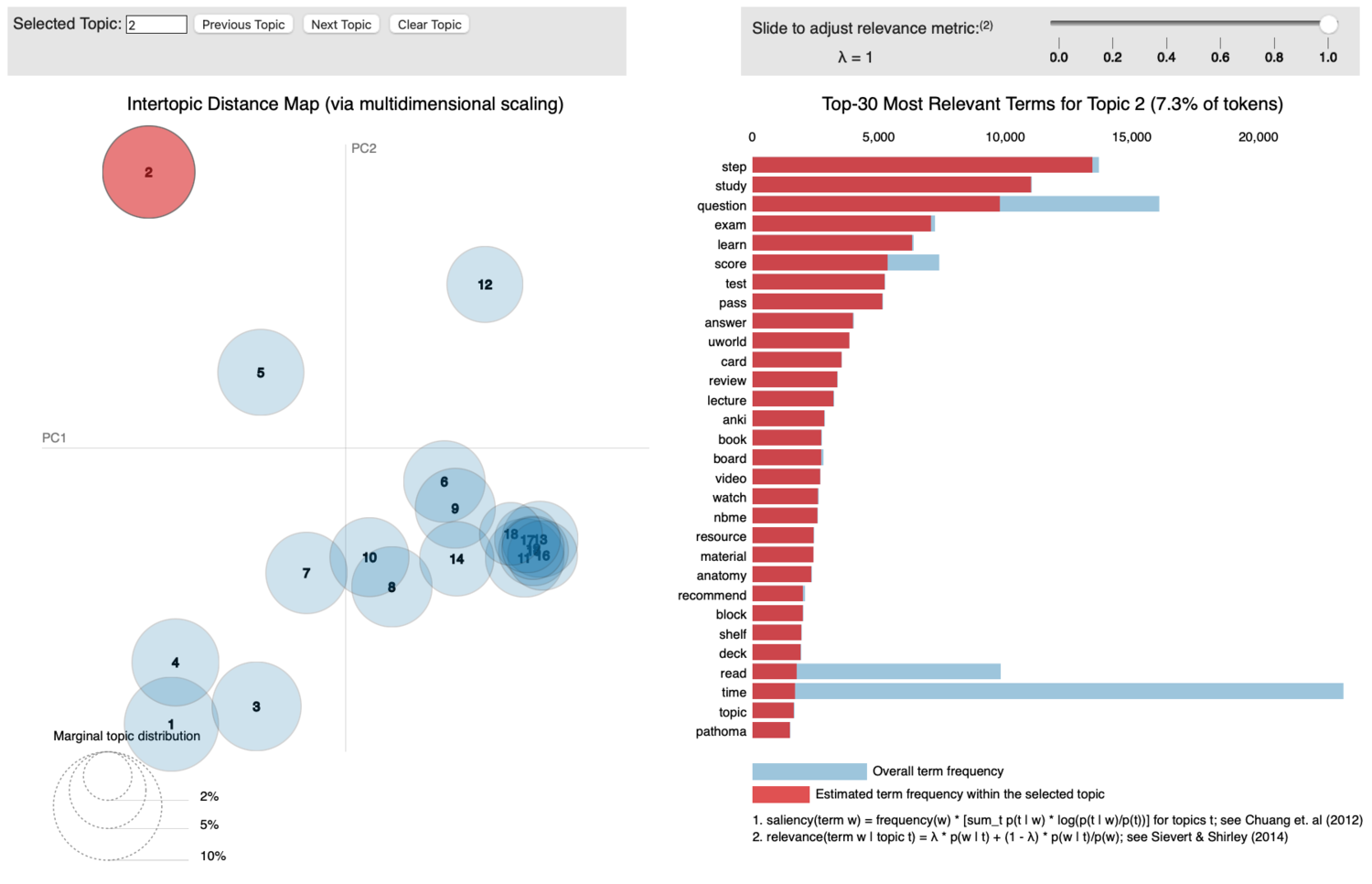
Topic 2 seems to be talking about the actual content of medical school and studying. You see the obvious identifiers like ‘study’, ‘exam’, ‘lecture’ etc… For the uninitiated among you:
- ‘Step’/’NBME’ are referring to any of three major board examinations which are weighed rather heavily in determining where students attain residency training and (to an extent) which medical specialties are open to them. This is a big one and it is featured prominently not just in this topic, but several others.
- ‘Anki’/’UWorld’/’Pathoma’ are popular studying resources which are utilized heavily. Anki is a spaced-repetition app, UWorld is the most popular question-bank for board prep, and Pathoma is the most popular study resource for Pathology (shoutout to Dr. Sattar).
Let’s call this one, “Med School” and go find something else.
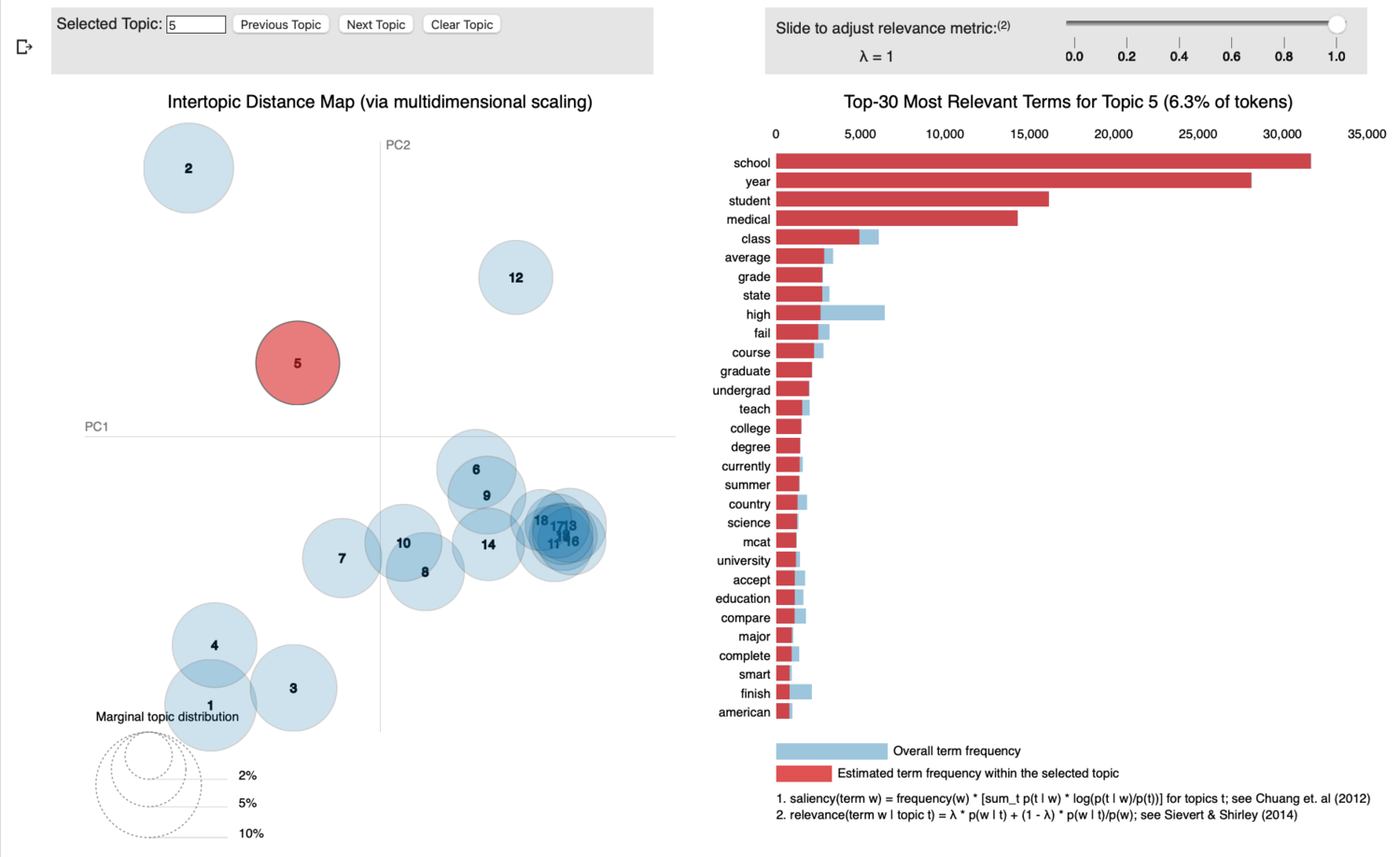
Topic 5 seems to reference a bunch of stuff related to getting into medical school in the first place: ‘mcat’, ‘graduate’, ‘undergrad’, ‘college’, ‘degree’, ‘major’ point me in that direction. I think is probably prospective medical school applicants asking questions, or people talking about process of getting into medical school in the first place (it’s hard and pretty competitive). Seems somewhat telling that even while in medical school, med students continue talking about getting into school in the first place. So let’s call this one “Med School Admissions”.
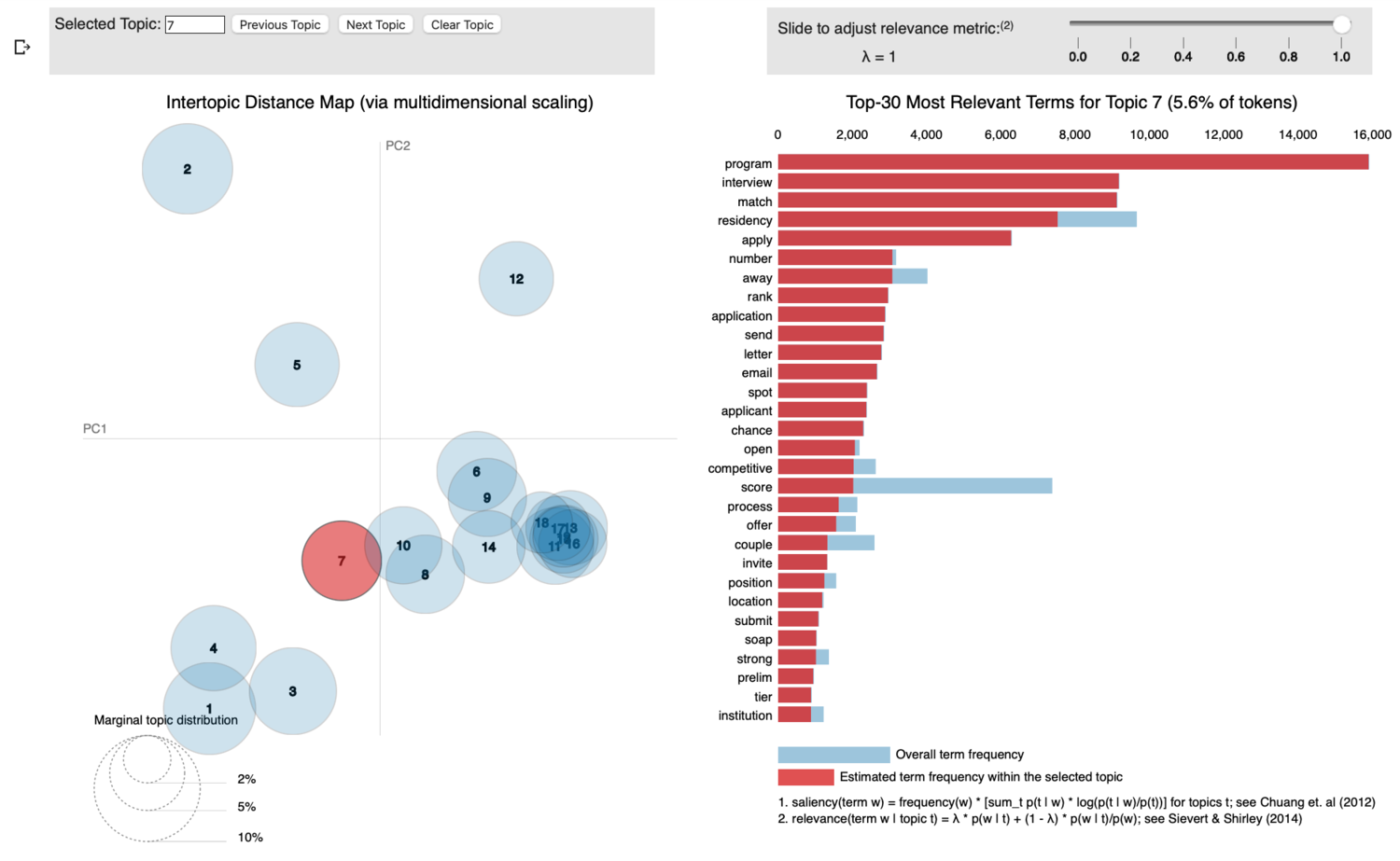
Topic 7 is pretty obviously about the Match. The Match is the process by which 4th year medical students obtain residency training. It involves a (pretty much year-long process) of:
- Preparing a long, tedious application
- Submitting applications (which is costly)
- Flying around the country (during non-pandemic times; also very costly) to interview with programs
- Submitting a rank-order-list which gets matched against the residency programs’ match-lists
- Finding out where you’re going to spend the next 3-7 years of your life, if anywhere at all.
It’s an incredibly stressful time and the topic seems to reflect that. So we’ll call this one, “Match”.
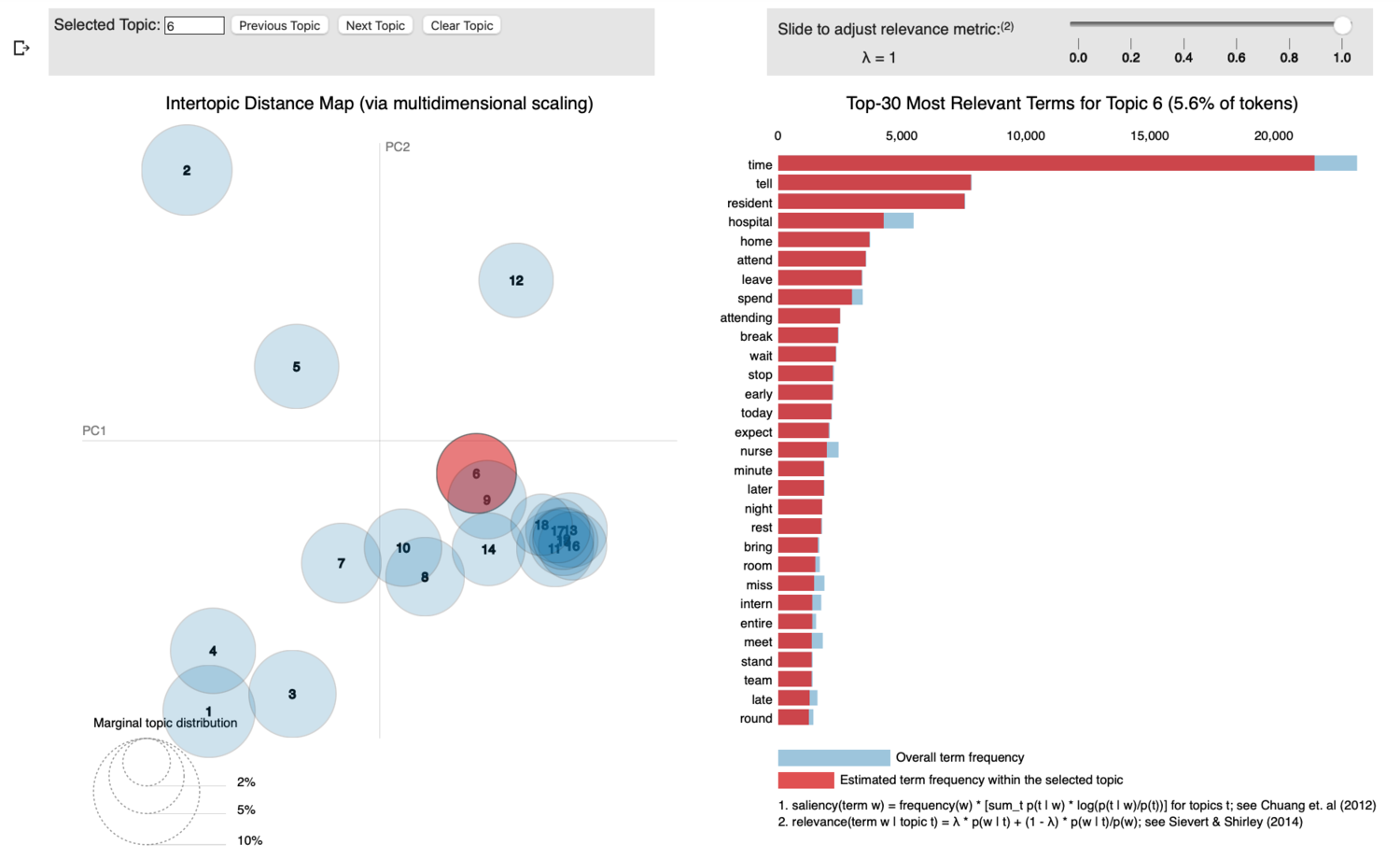
Topic 6 appears to get a little squishier (note the proximity of this circle to a large cluster of other circles); to the untrained eye this may appear to be about any number of things, but I’m 90% sure that this topic is about clinical rotations. Medical students spend the first two years doing book learning. Your mileage may vary, but it’s mostly learning and preparing for Step 1, with a smattering of learning physical exams and what I liked to call ‘Human Interaction 101’, which involved learning how to maintain eye contact, feign compassion, and not refer to patients by their room number and chief complaint.
In stark contrast, during the last two years students spend most of their time in hospitals and clinics. They generally spend their days gathering information about patients, writing notes, babbling incoherently on rounds, and generally finding new ways to be wrong about medicine. It is at this point that students quit complaining about Step 1 and lectures (because they’re done with that stuff) and instead focus on learning how to Doctor; thus all the mentions of: ‘attending’, ‘resident’, ‘intern’, ‘round’, ‘team’, and ‘nurse’. All people/things you start dealing with in the hospital. What’s really telling here is that along with these mentions come the words: ‘time’, ‘home’, ‘leave’, ‘early’, ‘break’, ‘night’, ‘stand’ and ‘rest’. This is also a time where time management begins presenting unique problems for students; you’re expected to arrive early (as early as 5AM!), complete all your work, leave late (sometimes as late as 7PM!), and then go home to study for your exams. Also it involves a whole lot of standing around waiting to be told to do something (or rather, scolded for not having already done something). Let’s call this one ‘Clinical Rotations’.
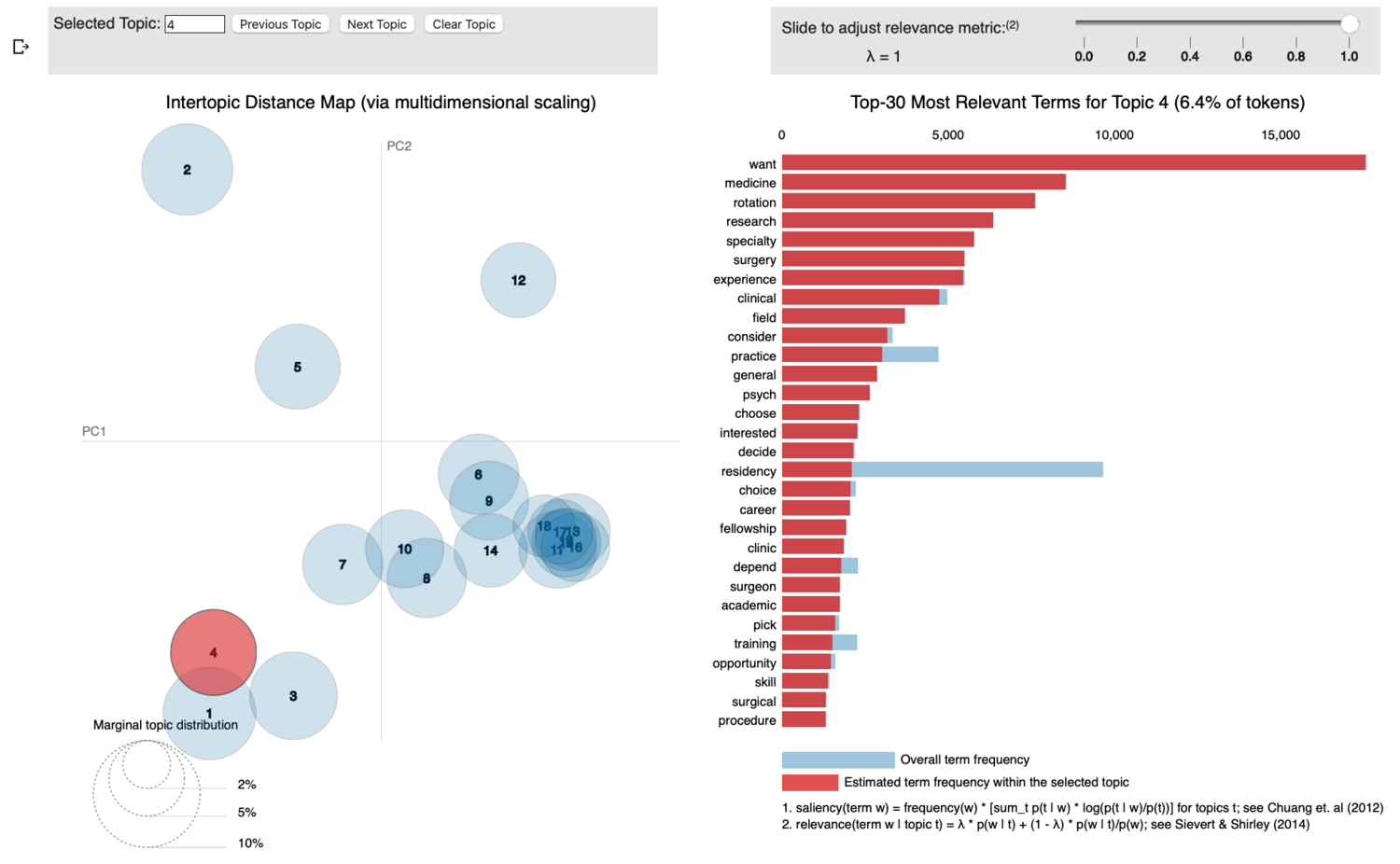
Topic 4 is pretty transparently about students choosing a medical specialty. This is determined by which residency programs you apply to, but that’s a result of a bunch of self-selection based on competitiveness like board scores, clinical experience, school prestige, and having done relevant research. It’s sort of a big deal for students to select a specialty and definitely a hot button topic. Not at all surprised that this showed up. “Specialty’‘.
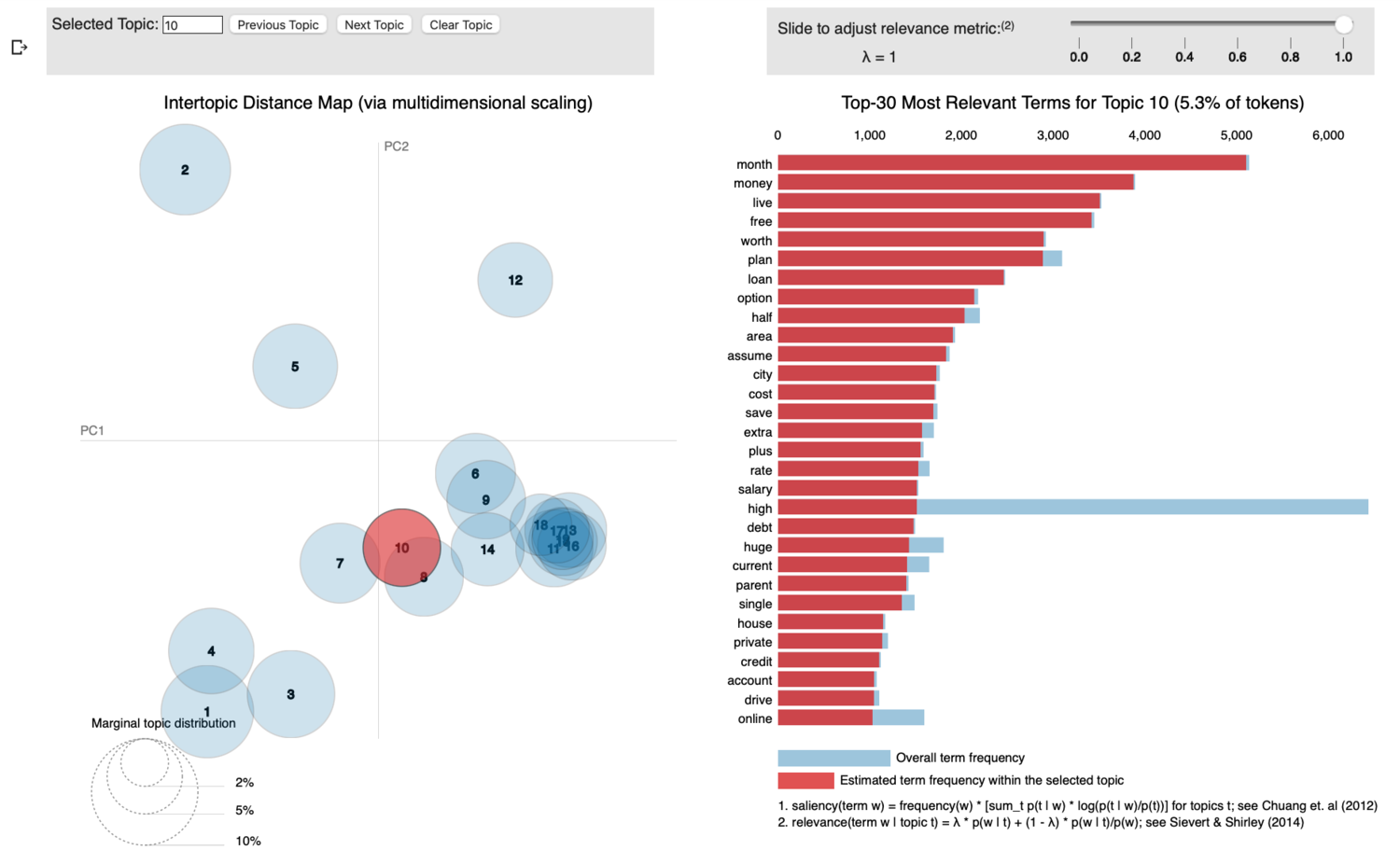
Topic 10 may come across as perhaps a little touchy, but it’s definitely about lifestyle (i.e. money). I’d really hate to fuel the super cynical (but broadly misguided) view that medicine is all about profit maximizing for doctors, but there are a few (definitely not self-serving) things you need to understand.
Becoming a doctor is expensive. Average medical student debt is something like $230,000 with undergrad combined, with ~18% of students graduating with over $300,000 in debt. I know a few of these people and let me tell you, they are stressed about it a lot. You may be thinking, “yea but then you’re a doctor and you’ll make like a bagillion dollars”, and you’d be wrong. During residency training, you make something like $50-70,000 per year (pre-tax!), and only sometimes is that adjusted for cost-of-living. It may sound out-of-touch, but you can’t afford to live in Manhattan on that salary and also be close enough to work so that you can stumble home after a 30 hour shift. But then afterwards you can start making money and on average that medical school debt is paid down in 13 years, which you know, isn’t the worst but also isn’t super great either.
But regardless of the specifics of debt burden for med students, there is certainly a lot of interplay between what specialty you practice, where you do it, and your lifestyle. The pay scale for doctors is (not literally everywhere but in general principles) related to demand; places where there is a lack of medical care (think low density, fewer cool things to do) pay doctors more to work there. So if you want to be a specialist in underserved rural South Dakota, you can probably find a hospital to pay you enormous sums of money, but the reason they need to pay you so much is because not many doctors want to work there. (Not a knock on underserved/rural areas! But by the numbers, you can see how scarcity gets generated). ‘Lifestyle’.
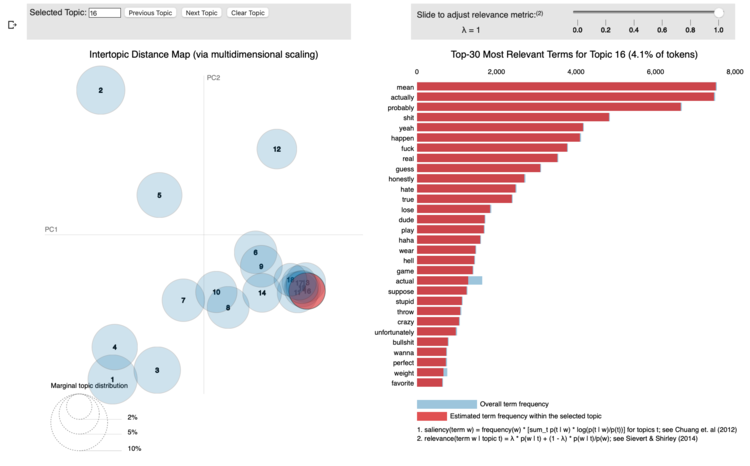
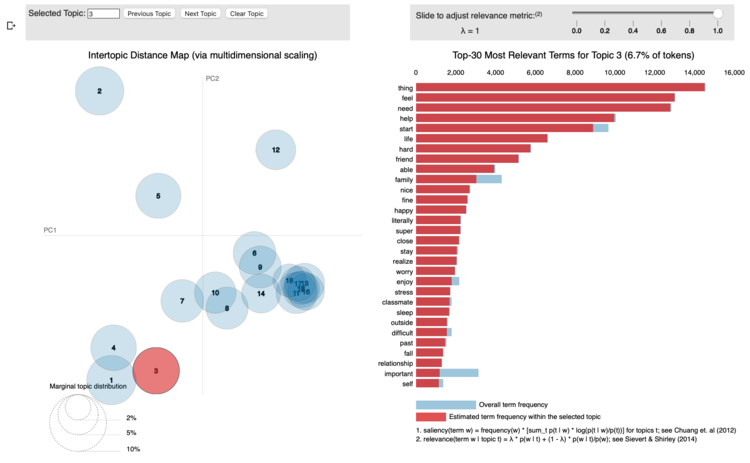
These next two were interesting to view together.
- Topic 16 seems to be venting and I’ve named it as such. Quite a bit of profanity, and other words that imply (when thought of together) someone is upset about something: ‘honestly’, ‘probably’, ‘hell’, ‘mean’, ‘actually’, ‘hate’. You get the picture. Medical school is hard.
- Topic 3 I ended up calling ‘therapy’. It has words like: ‘feel’, ‘need’, ‘help’, ‘life’, ‘stress’, ‘relationship’, ‘family’. This is of course different than venting, but appears to represent students talking about their personal lives. Again, medical school is hard.
Erm…Cool?
Yea so this was pretty fun. I ended up learning quite a bit about a handful of python libraries and I’ve finally gotten around to figuring out how to use bash and git which I’ve been putting off because it looked scary. I got to learn the value of Pandas (🐼🐼🐼) after trying to open a csv file with 1.5 million rows and watching as my precious MacBook was brought to its knees. More importantly, I now have a semi-solid framework for running topic modeling on a variety of datasets if I ever want to replicate this for something of actual value.
You can also use the model to guess what a new post is talking about, and this would be pretty useful in oh, let’s say, identifying trends in things over time. So for example if you plotted the frequency of when ‘Match’ comes up you’d find it starts in the Summer and culminates in March or something. You might also use the model to filter out posts you may find irrelevant to your purposes, for instance if you only wanted to look at how medical students use profanity or whatever, you could definitely tune the model to find those posts in particular. The world is your oyster.
One More Thing!
So I held onto one topic so that I could end this post with it. You know. For dramatic effect.
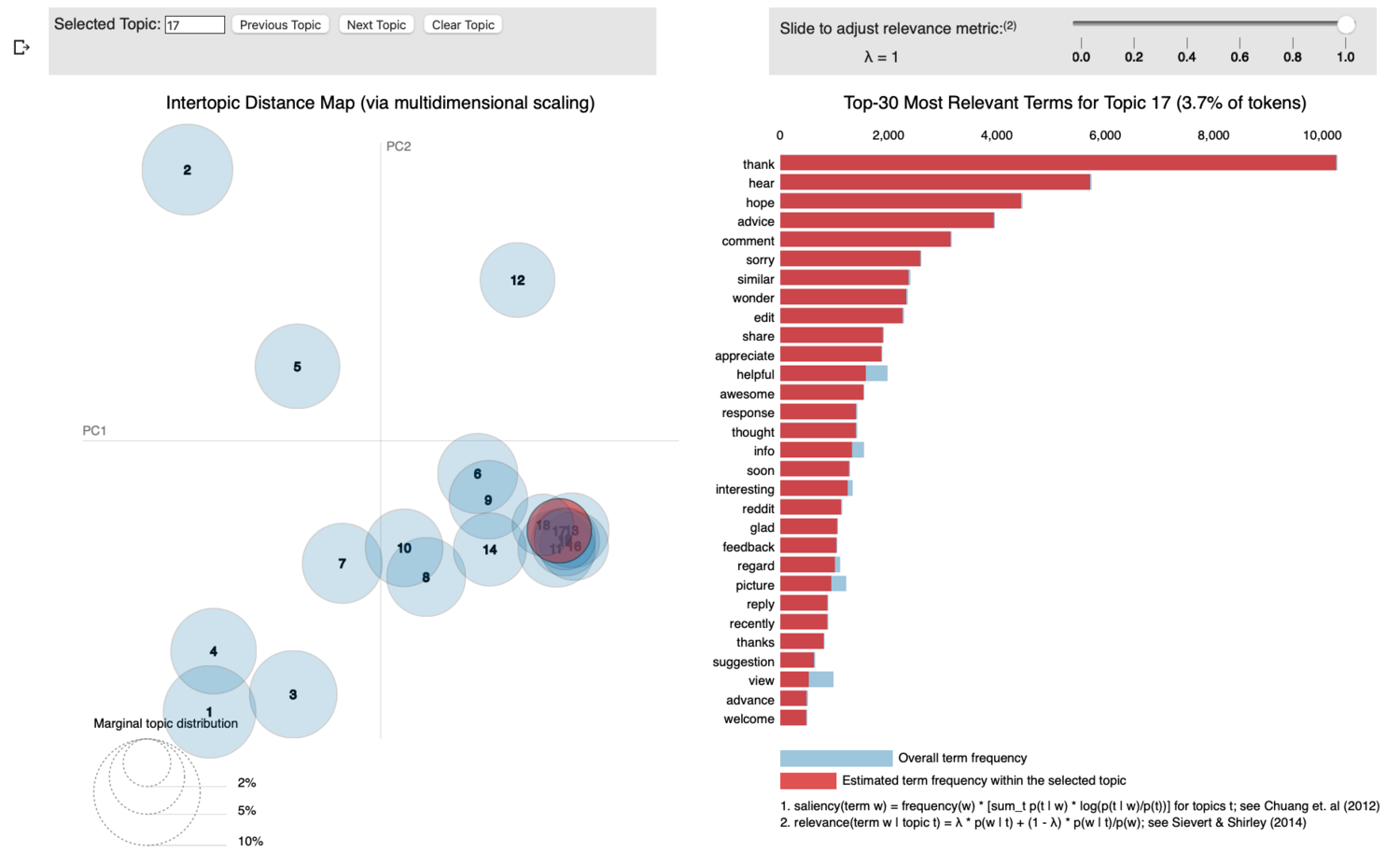
This is Topic 17. It overlaps pretty heavily with a bunch of topics, but also importantly with Topic 16. If you don’t remember, Topic 16 was called ‘Venting’ and was filled with profanity and was overwhelmingly negative. Topic 17 is notably very different. It consists of words like: ‘thank’, ‘hear’, ‘hope’, ‘advice’, ‘similar’, ‘share’, and ‘appreciate.
I call this one ‘Gratitude’. It appears to be a bunch of redditors thanking each other for the help, advice, and support that they’ve received. The internet is sometimes a pretty toxic place, but it can also be a gathering place where you can find others who share in your frustrations and who may be able to lend a helping hand or an empathetic ear (well, eye, finger. Whatever). It made me smile to see that this showed up as it’s own topic because it is a huge part of why 340,000+ medical students have gathered in this one corner of the internet. Medical school is hard, but talking to a bunch of other equally exasperated peers about it can help.